Apple M4 (6P + 4E), 16GB unified memory. All benchmarks are single-threaded.
In all plots, CORAL is benchmarked against OpenBLAS. Some routines also include Apple Accelerate. When Accelerate is omitted, it’s because its AMX-backed kernels on this M4 MacBook Pro are much faster and mask any comparison with OpenBLAS.
For sgemm, faer is included, also single-threaded.
Table of Contents#
Level 1#
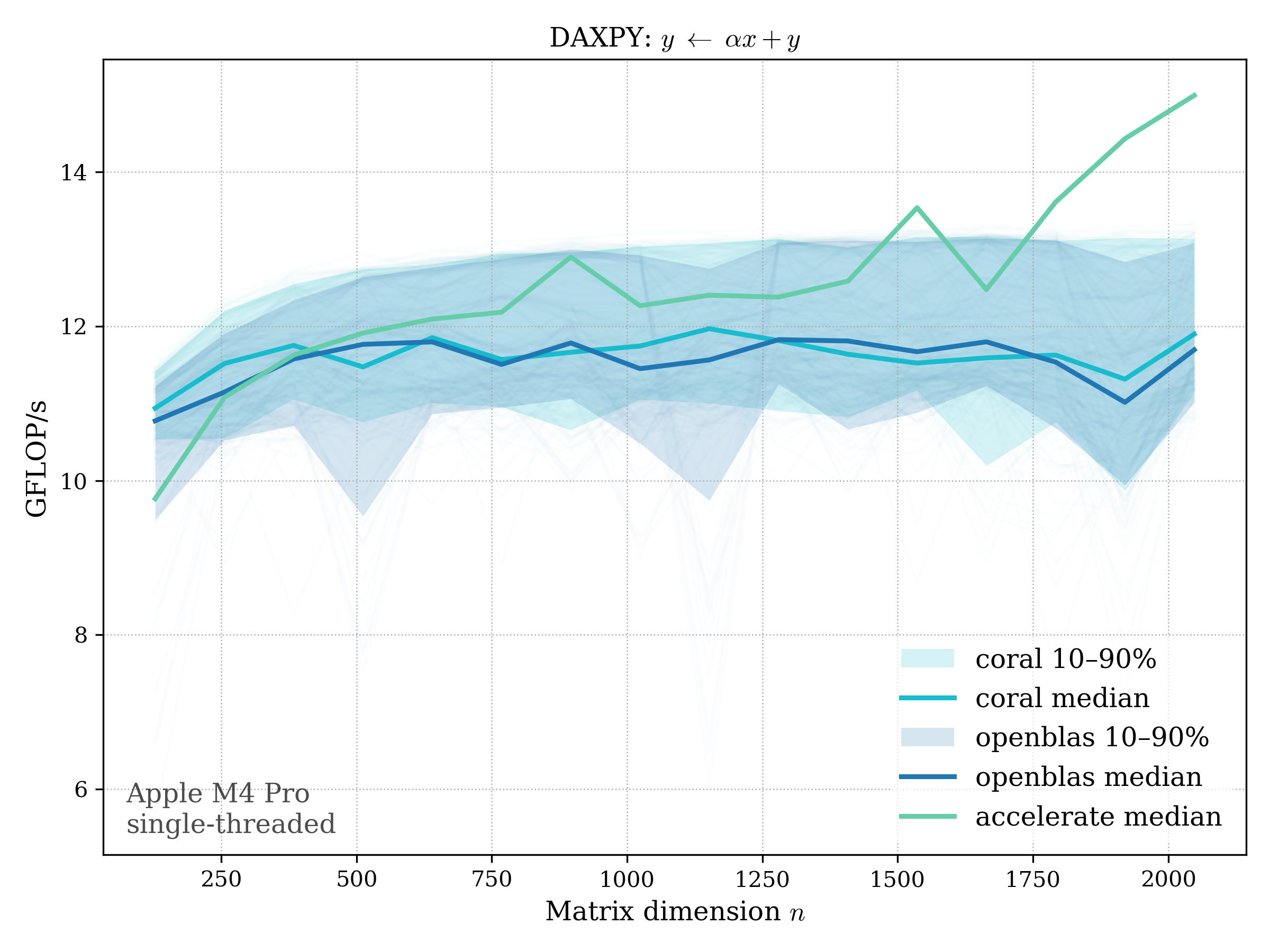
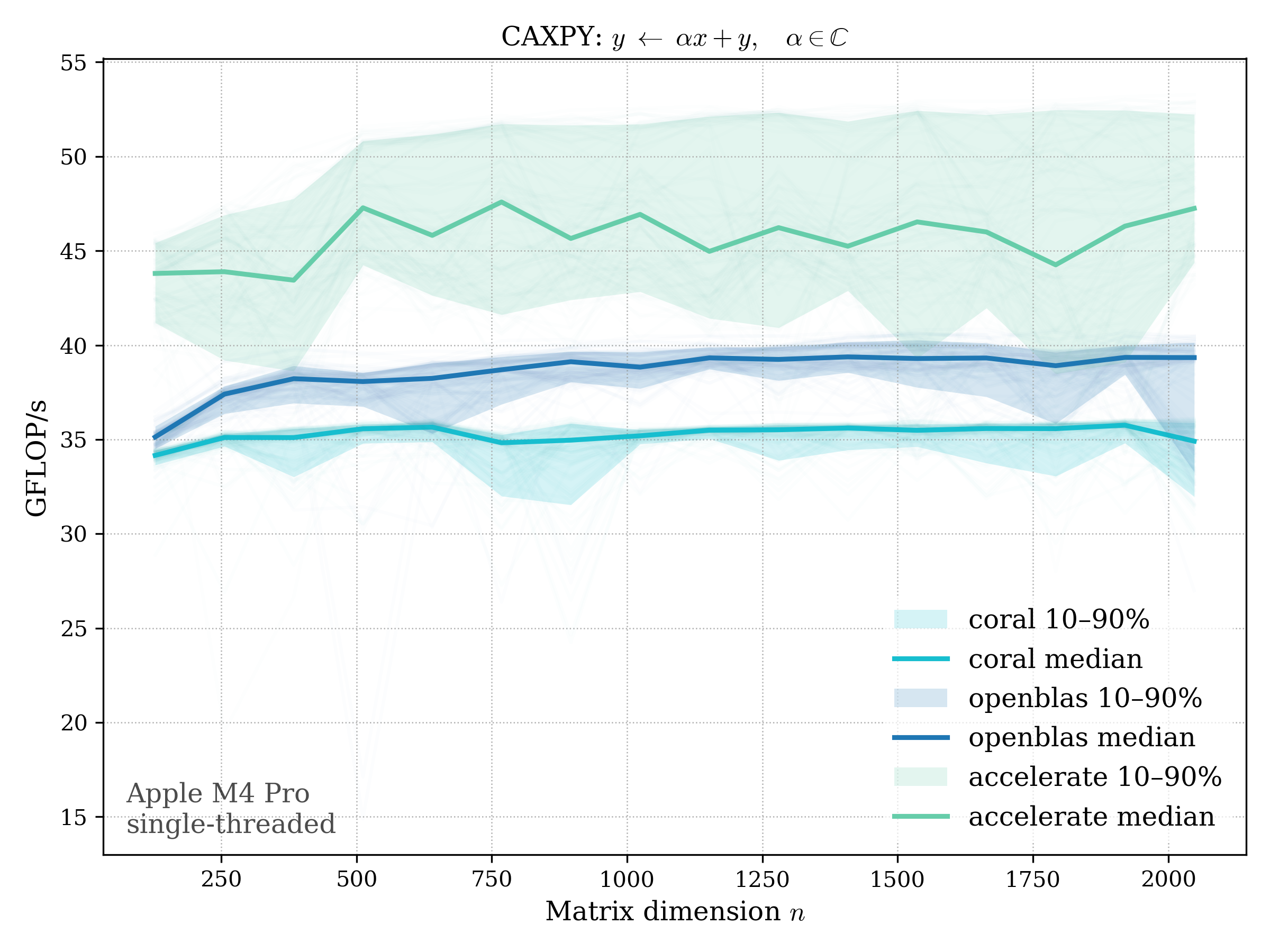
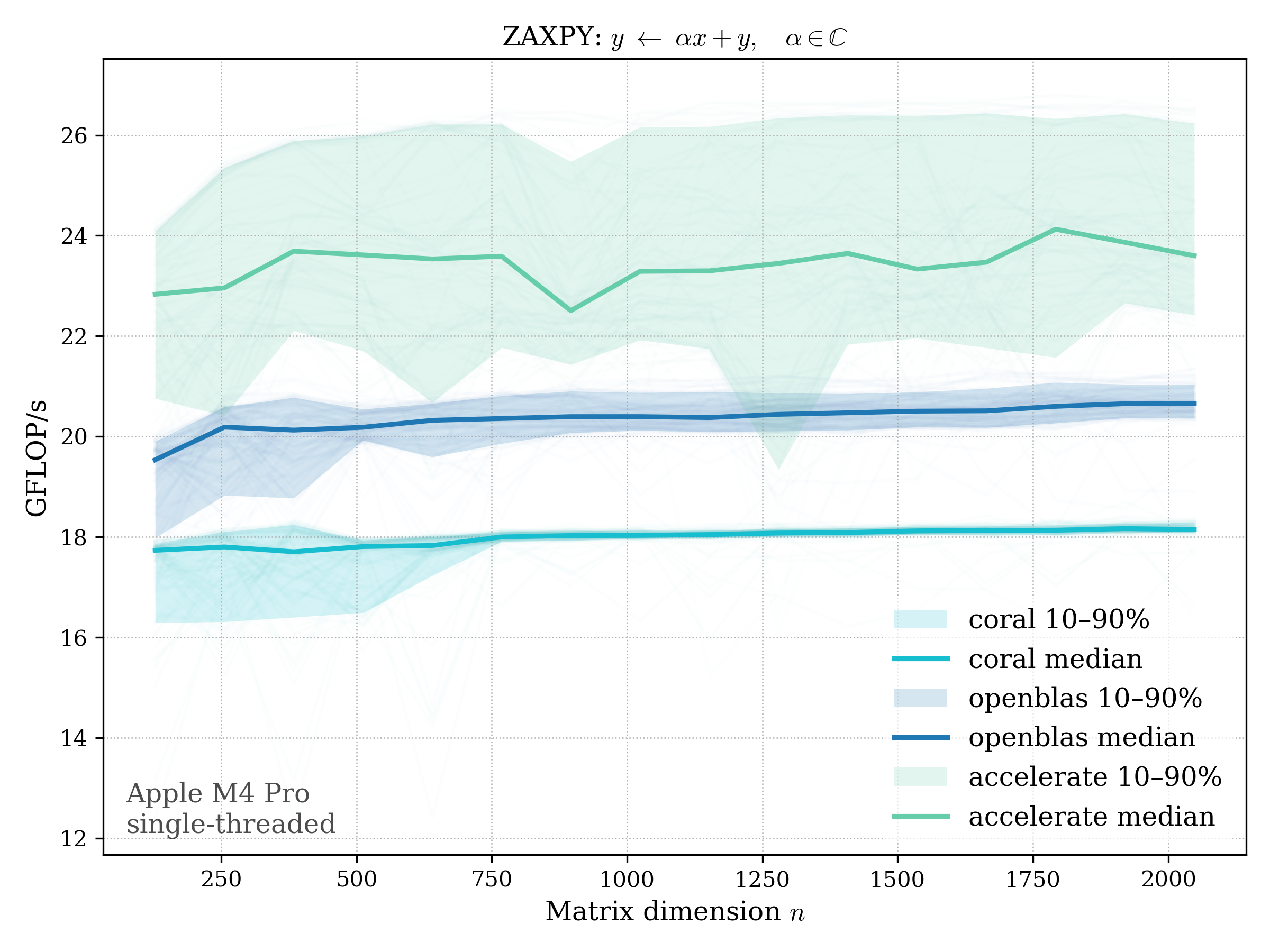
AXPY#
AXPY performs a scaled vector addition: \[ y \leftarrow \alpha x + y \]
f32#

f64#
c32#
c64#
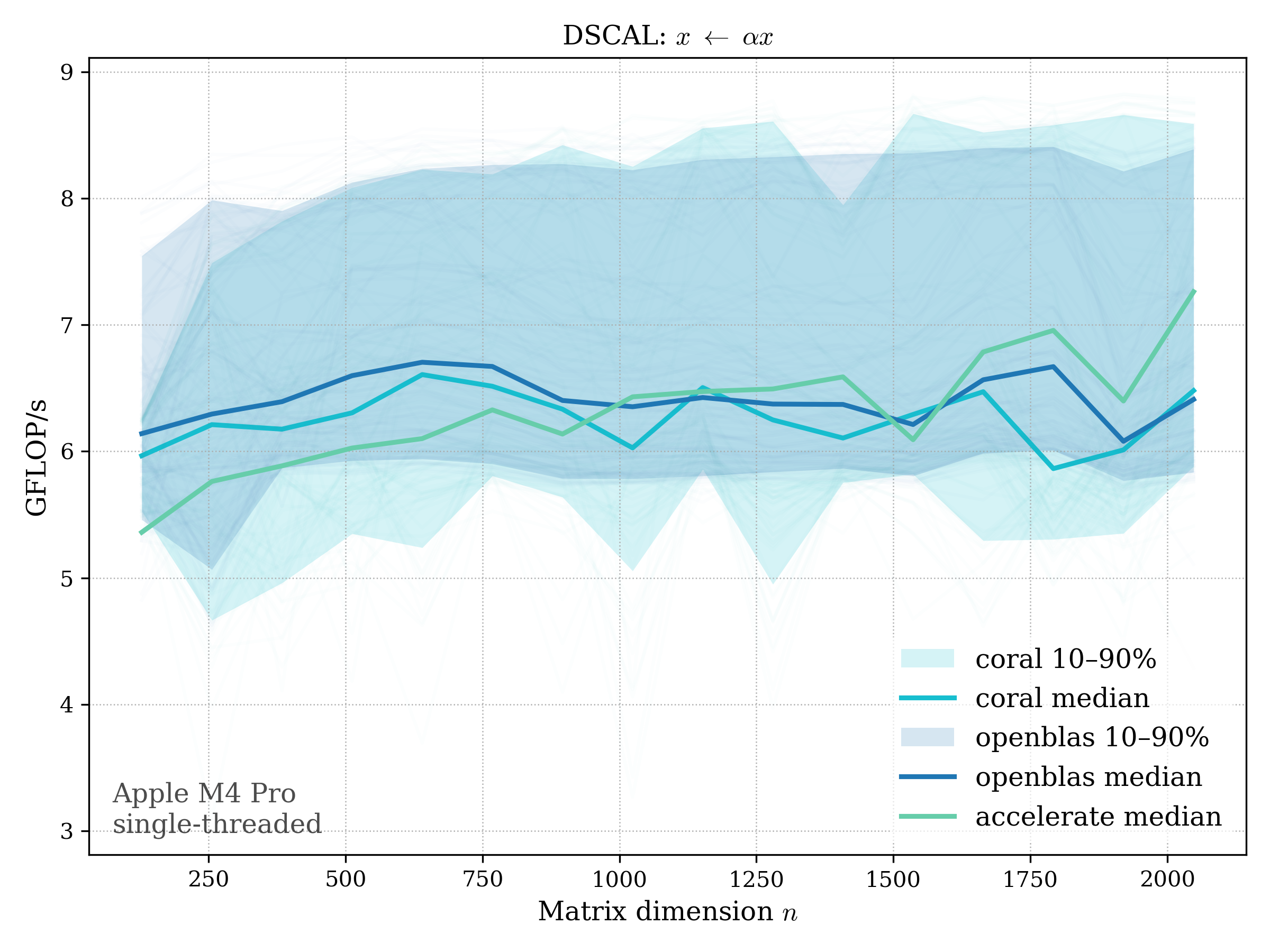
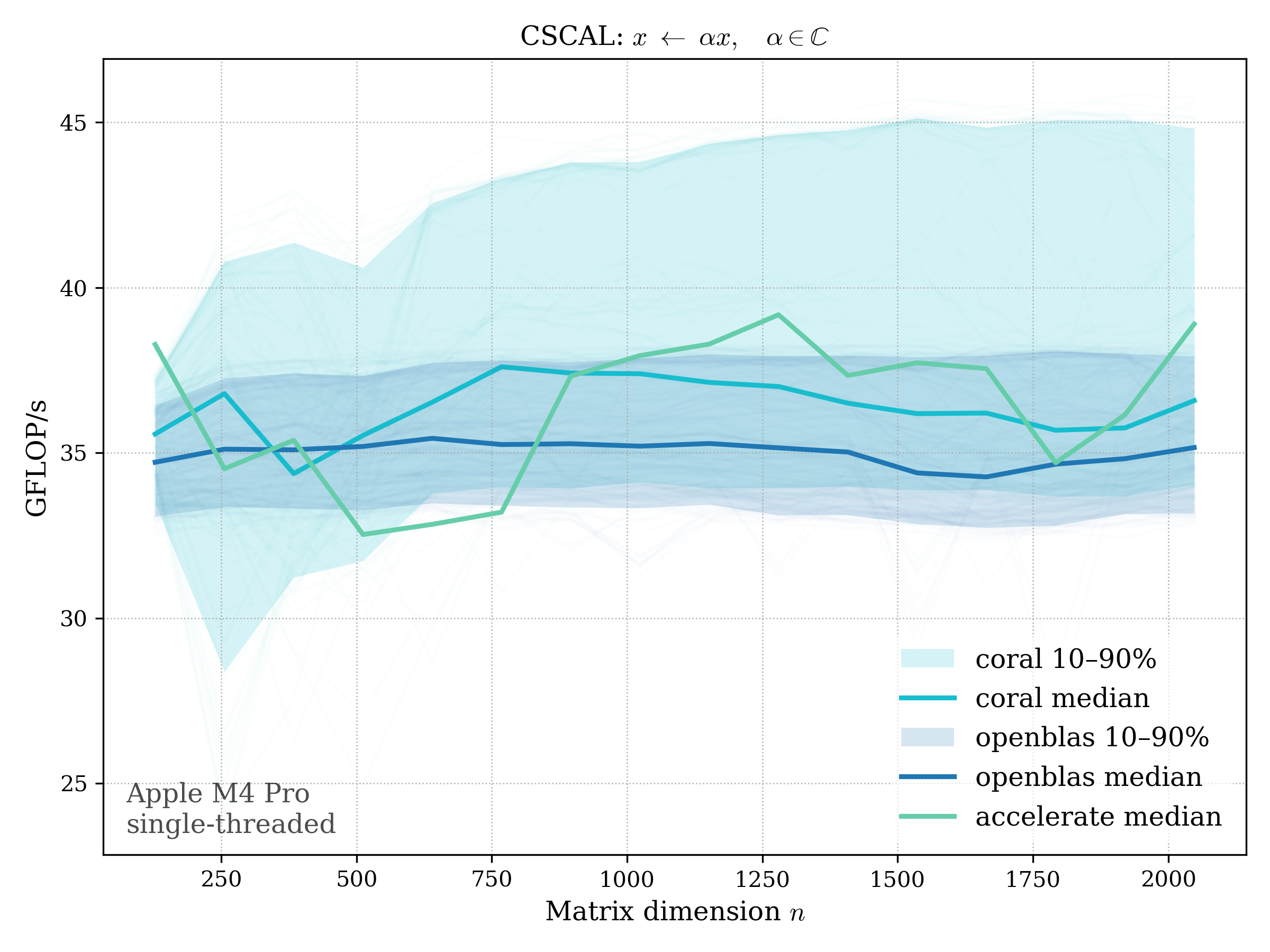
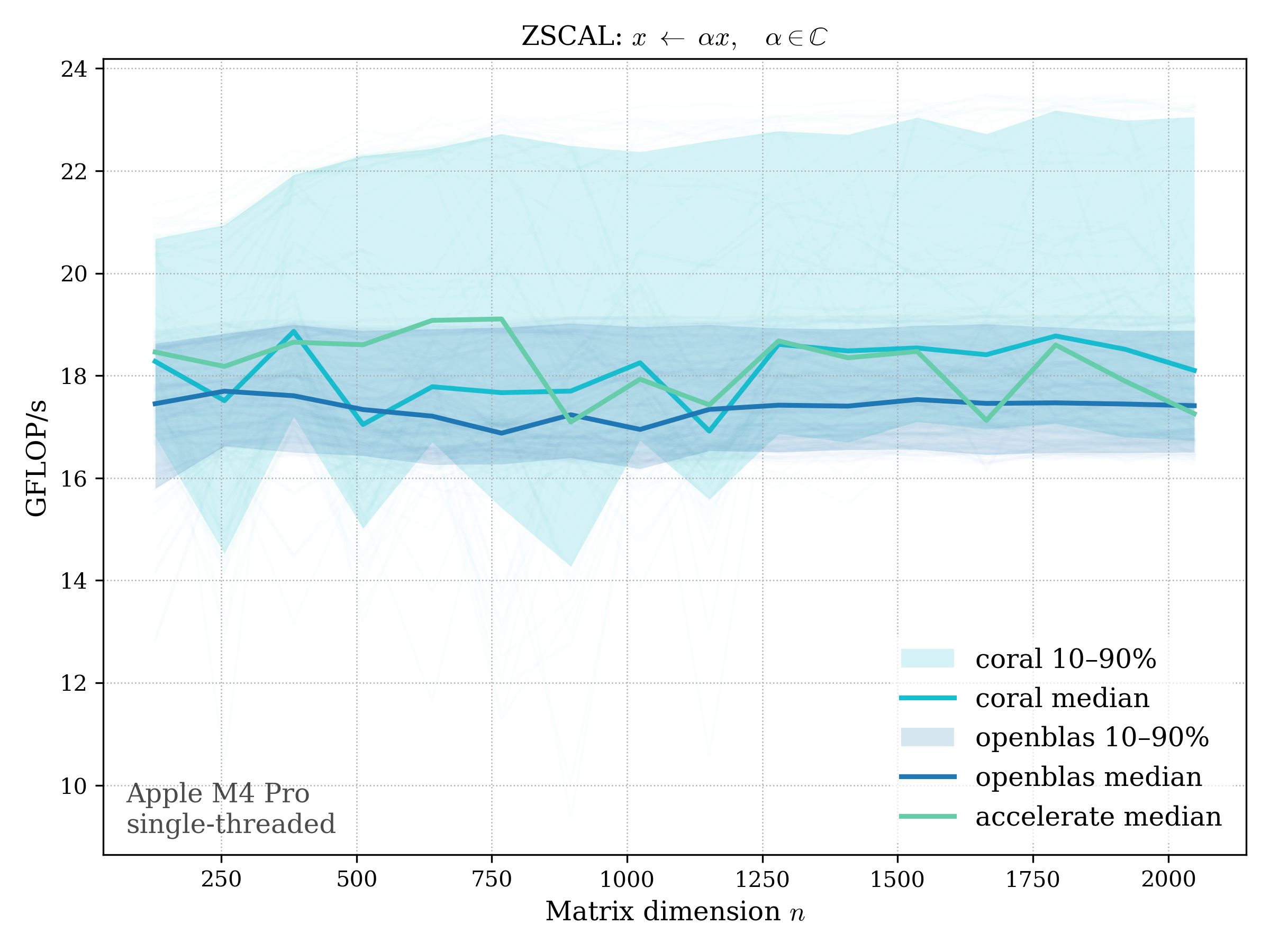
SCAL#
SCAL scales a vector by a scalar: \[ x \leftarrow \alpha x \]
f32#
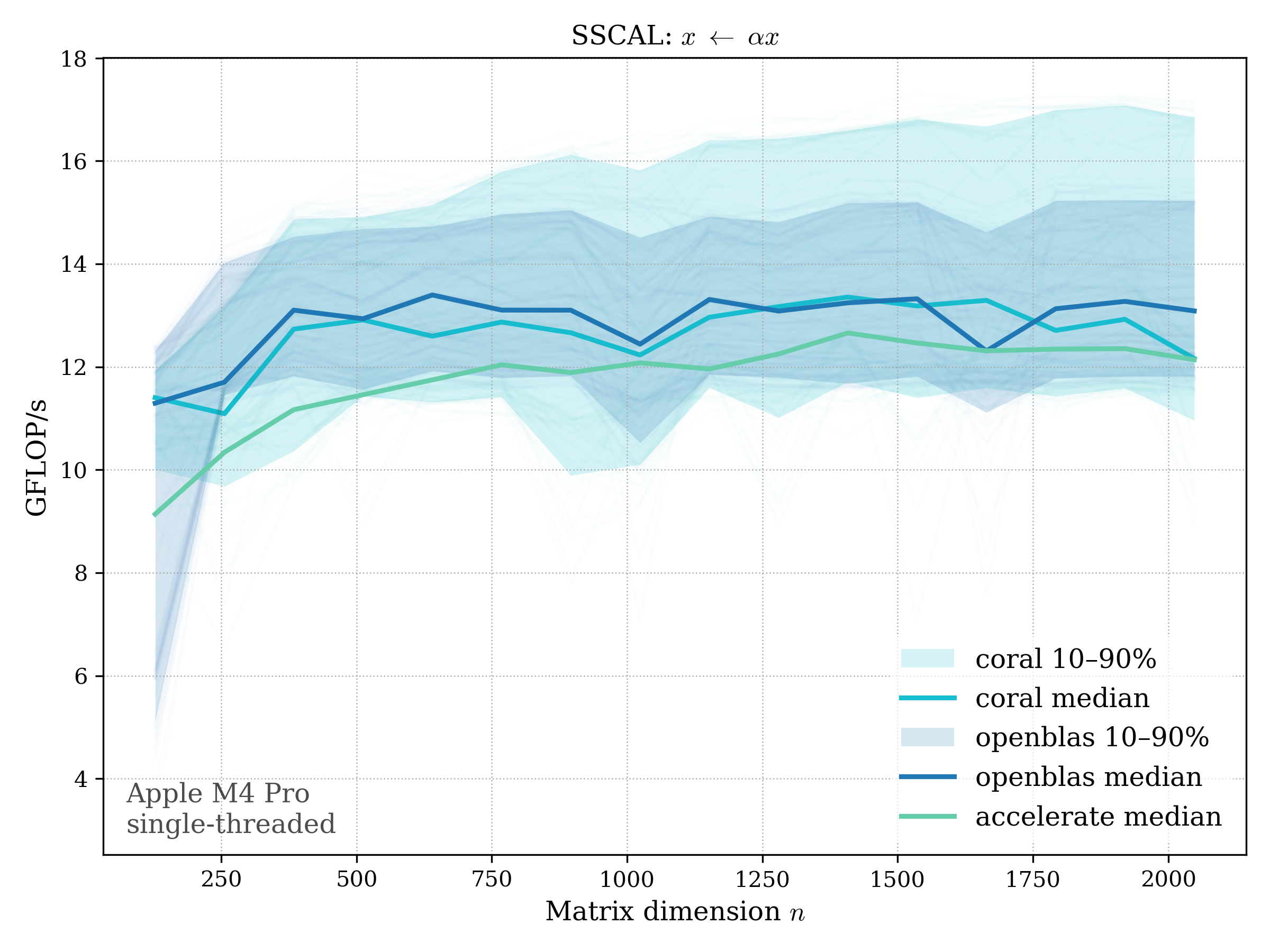
f64#
c32#
c64#
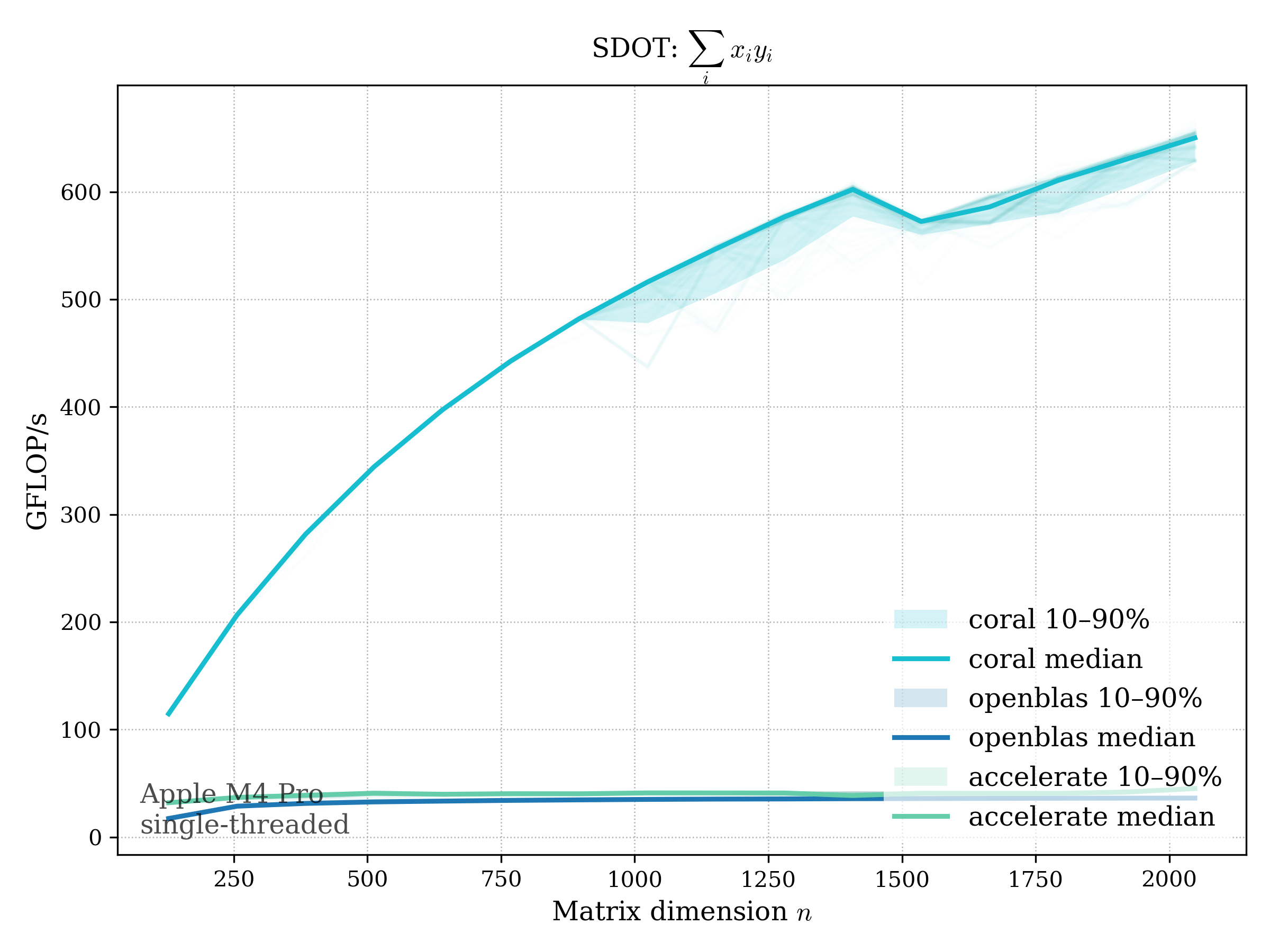
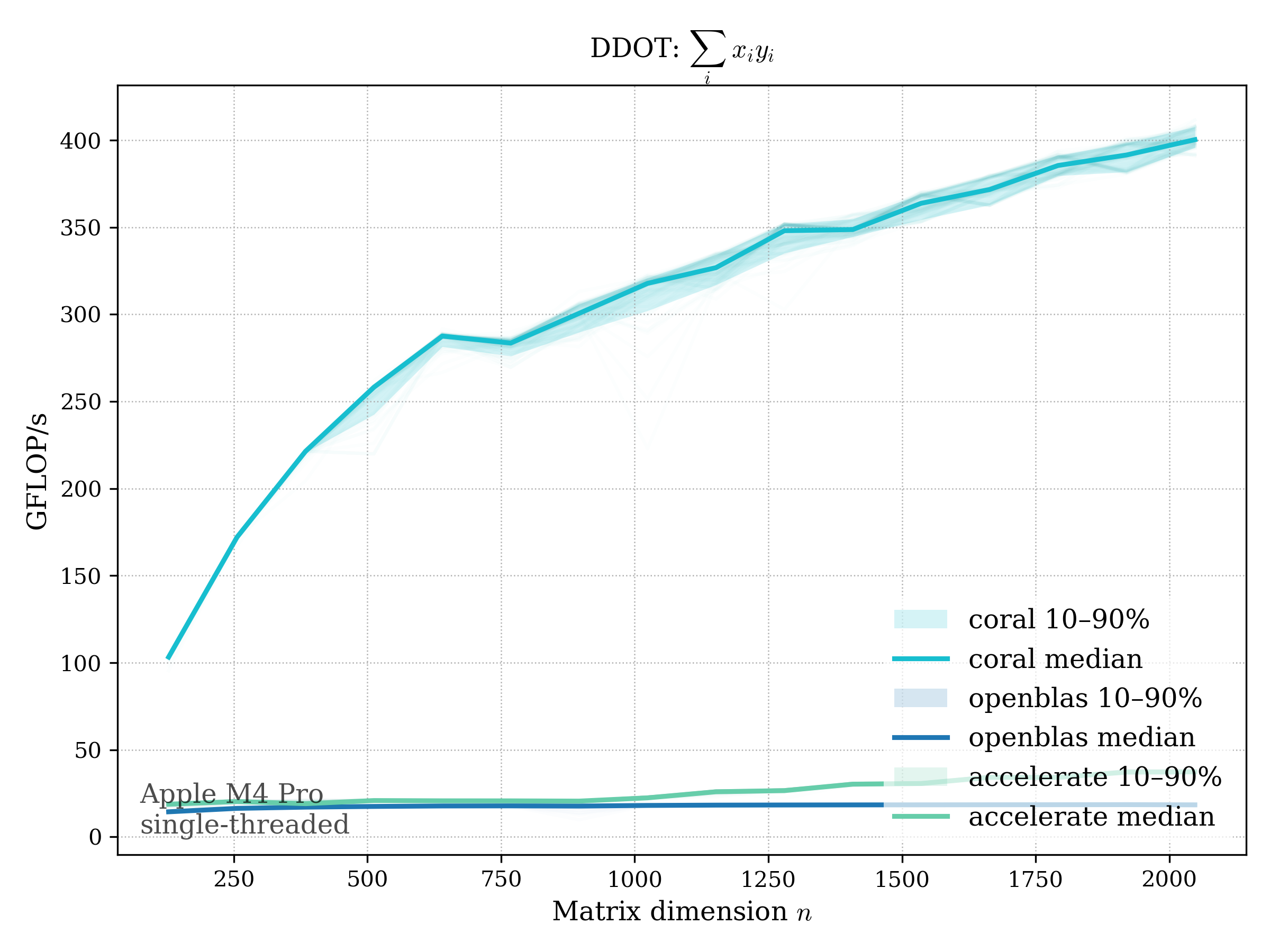
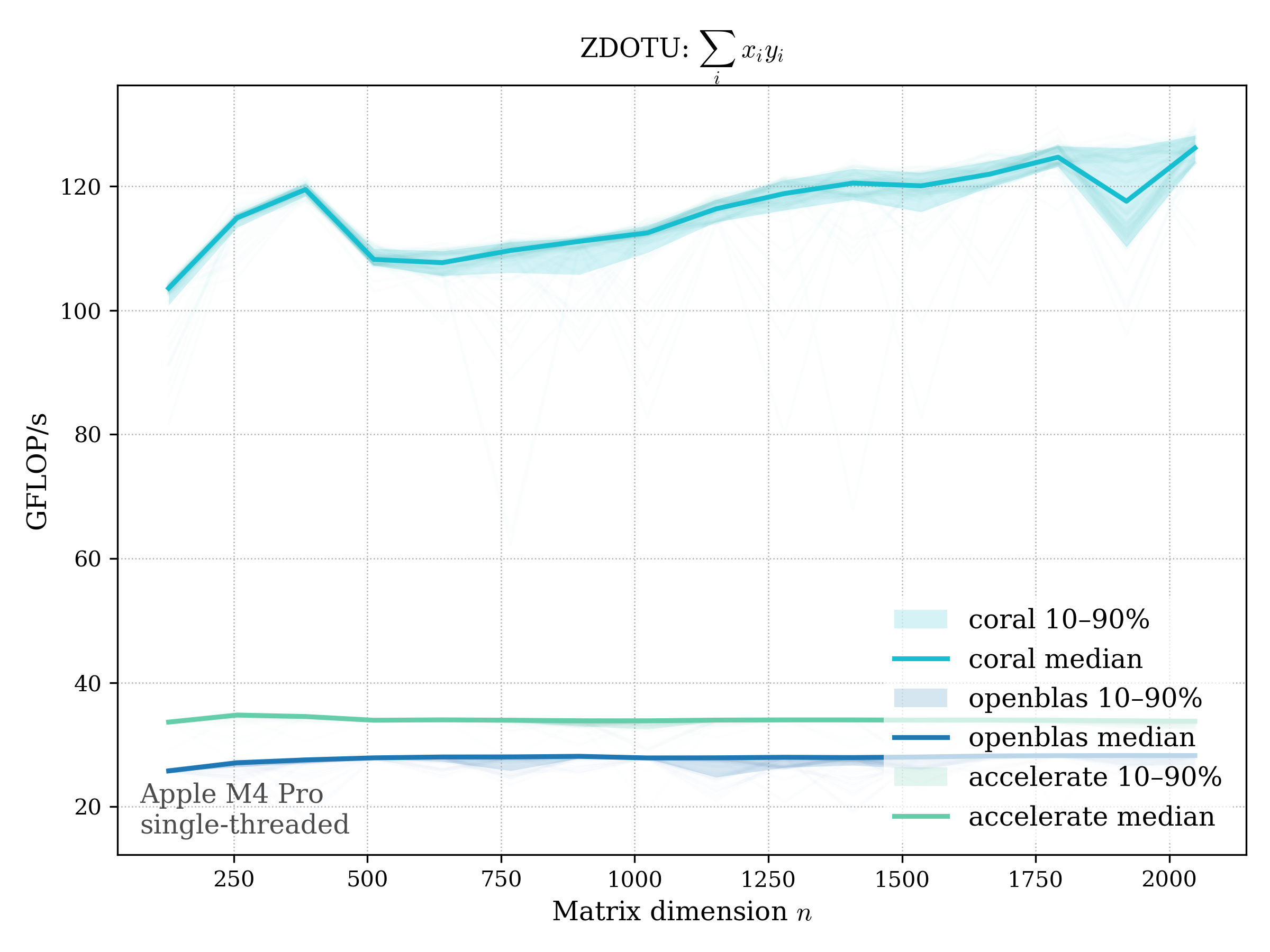
DOT#
Real dot product: \[ \operatorname{dot}(x, y) = \sum_i x_i y_i \]
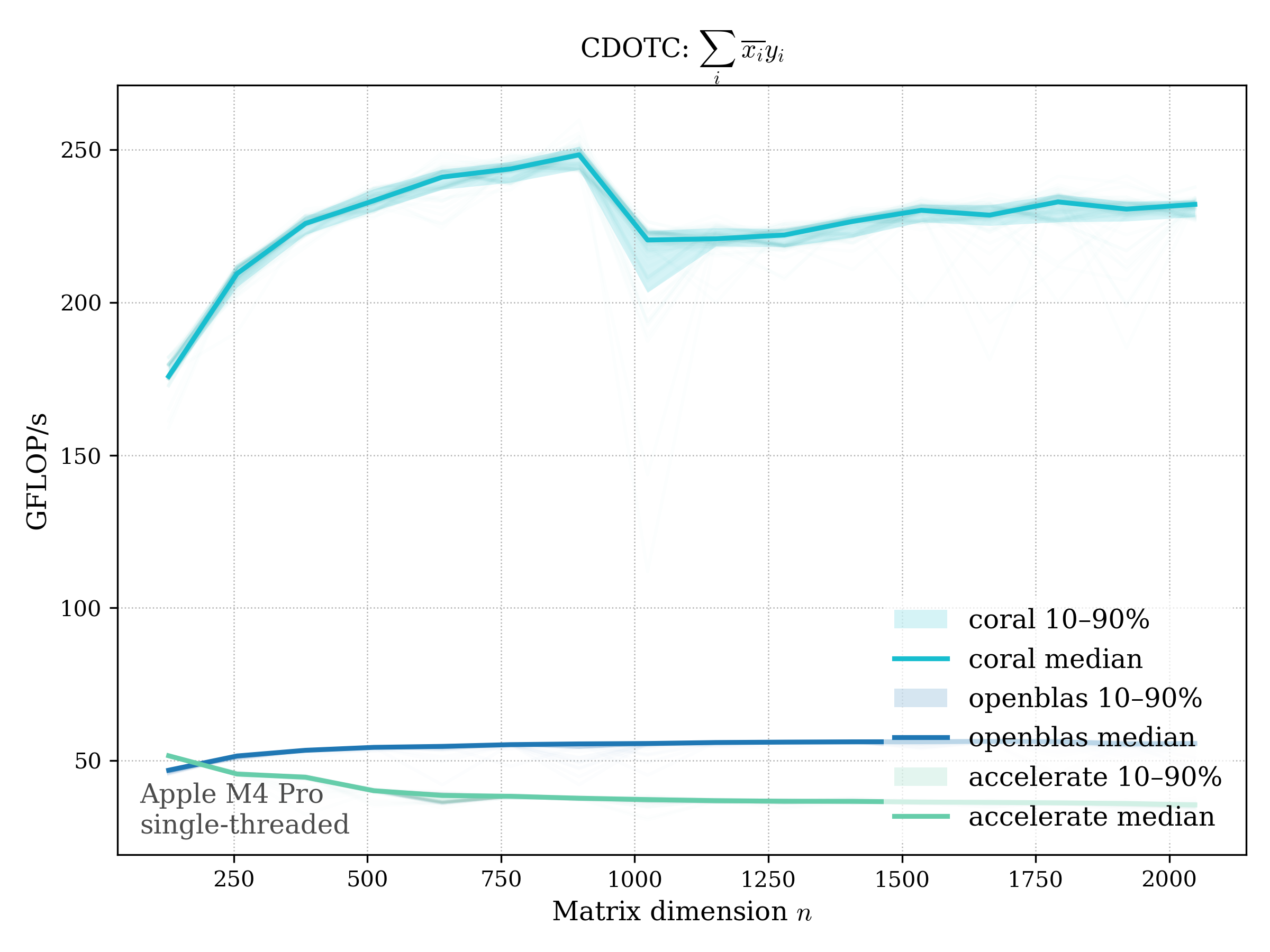
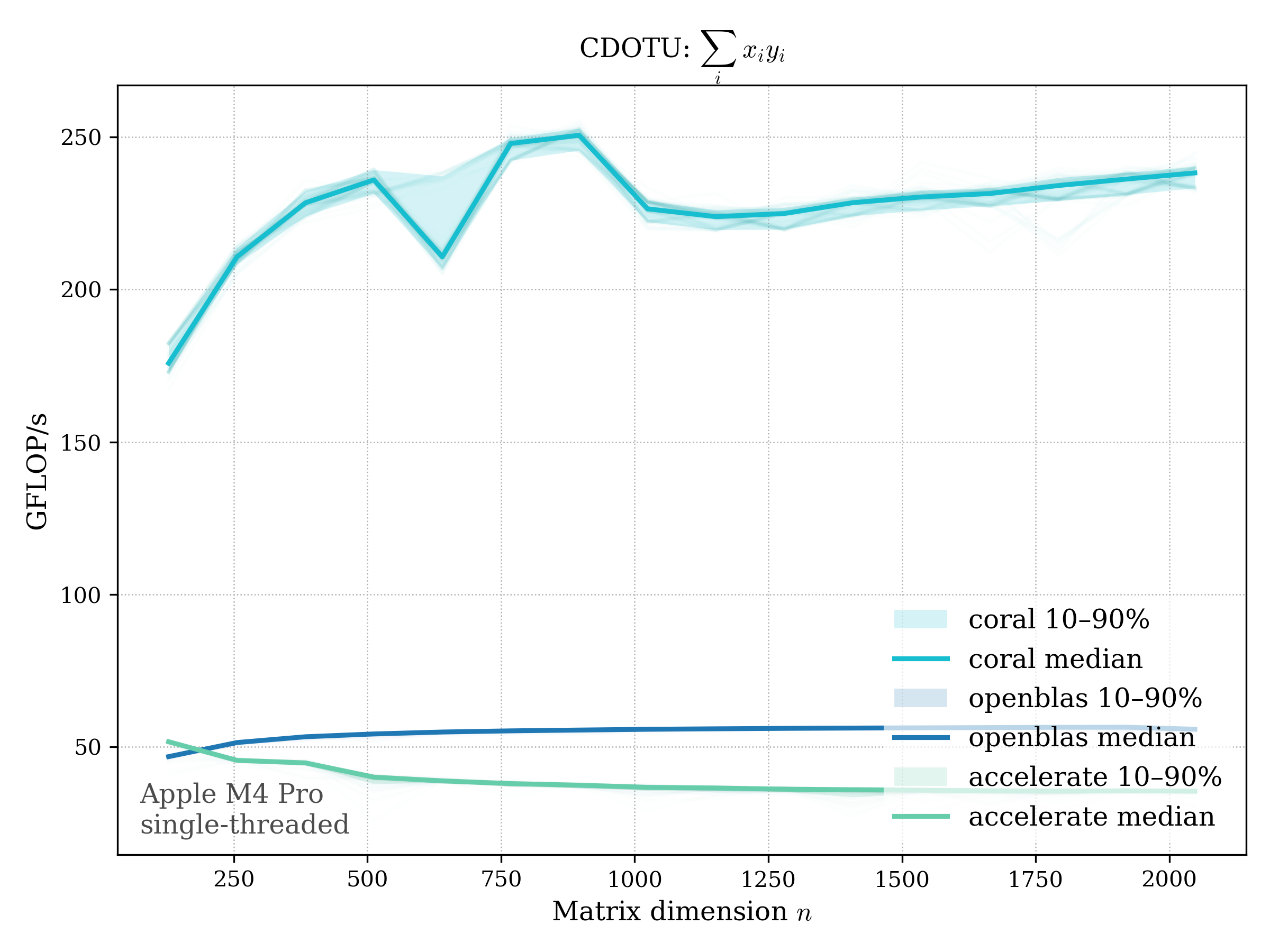
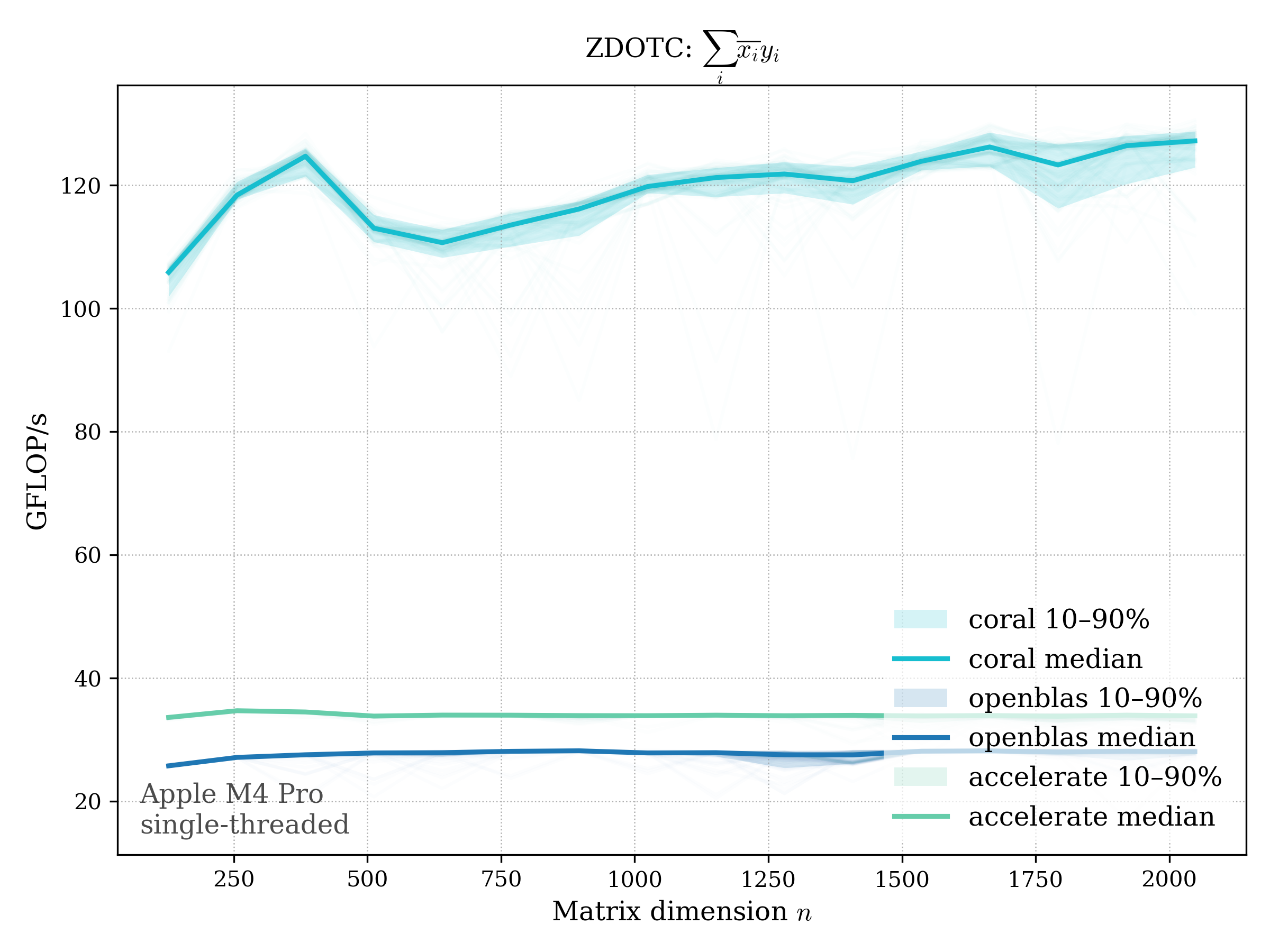
Complex variants:
- conjugated: \(\operatorname{dotc}(x, y) = \sum_i \overline{x_i} y_i\)
- unconjugated: \(\operatorname{dotu}(x, y) = \sum_i x_i y_i\)
f32#
f64#
c32#
conj (cdotc)#
unconj (cdotu)#
c64#
conj (zdotc)#
unconj (zdotu)#
Level 2#
GEMV#
Matrix–vector multiply: \[ y \leftarrow \alpha \operatorname{op}(A) x + \beta y, \quad \operatorname{op}(A) \in {A, A^T, A^H} \]
f32#
![]()
![]()
f64#
![]()
![]()
c32#
![]()
![]()
![]()
c64#
![]()
![]()
![]()
TRSV#
Triangular solve: \[ x \leftarrow A^{-1} b, \quad A \text{ triangular} \]
f32#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
f64#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
c32#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
c64#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
TRMV#
Triangular matrix–vector multiply: \[ x \leftarrow \operatorname{op}(A) x, \quad A \text{ triangular} \]
f32#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
f64#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
c32#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
c64#
LOWER TRIANGULAR#
![]()
![]()
UPPER TRIANGULAR#
![]()
![]()
Level 3#
GEMM#
Matrix–matrix multiply: \[ C \leftarrow \alpha \operatorname{op}(A)\operatorname{op}(B) + \beta C, \quad \operatorname{op}(A), \operatorname{op}(B) \in {,\cdot, {}^T, {}^H} \]
f32#
![]()
![]()
f64#
![]()
![]()
c32#
![]()
![]()
![]()