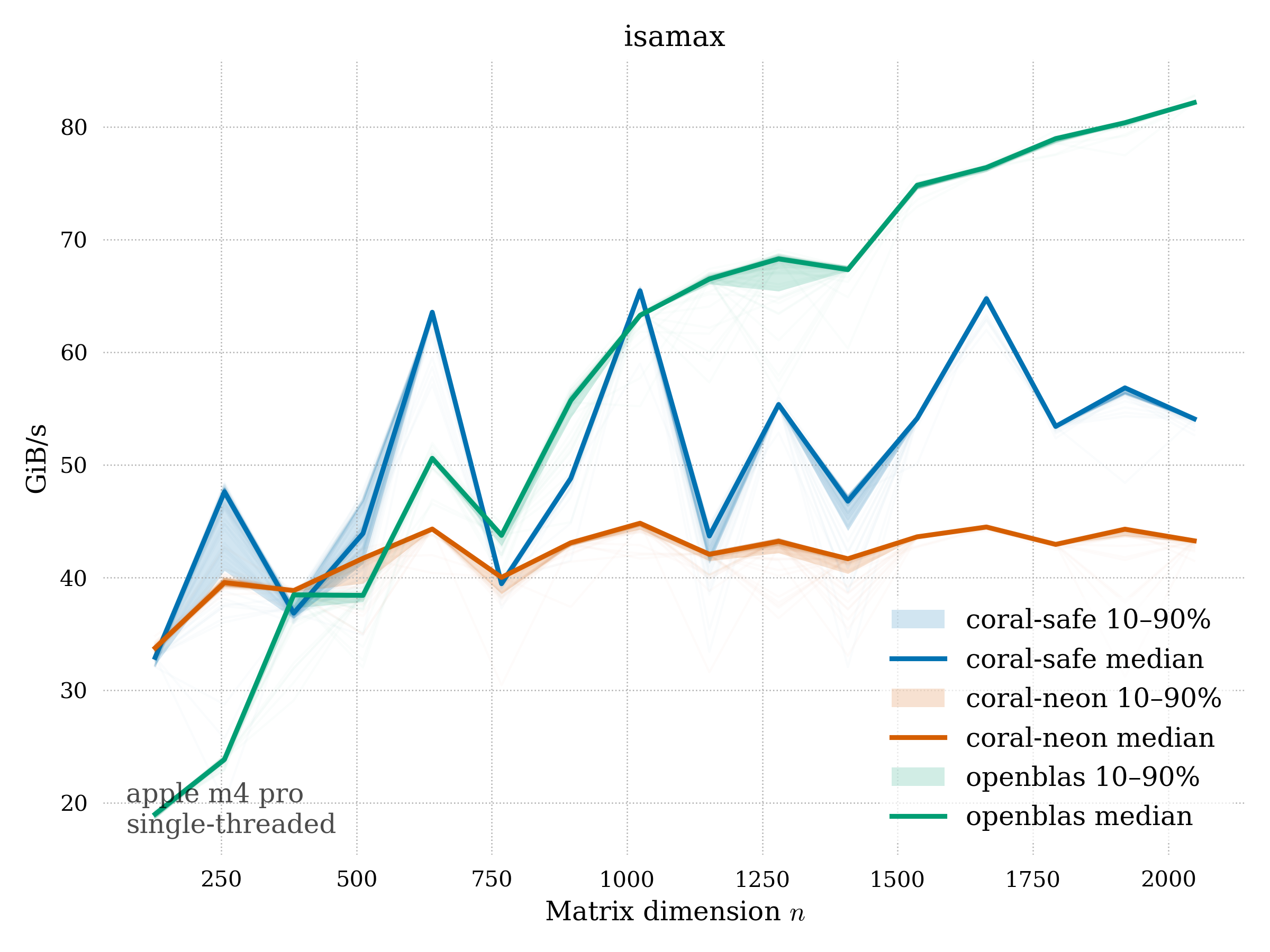
Apple M4 (6P + 4E), 16GB unified memory. All benchmarks are single-precision and single-threaded.
Each plot shows:
coral-safe(portable-simd, safe Rust)coral-neon(AArch64 / NEON)- a reference implementation:
- OpenBLAS armv8, or
- Apple Accelerate, or
- BLIS for
sgemm - faer for
sgemm/matmul
The OpenBLAS backend used is optimized for Level2-3. For some Level1 routines like SNRM2, I believe this backend just uses the reference, netlib algorithm.
Table of Contents#
OpenBLAS#
Level 1#
ISAMAX — index of max absolute value#